 | Content Disclaimer Copyright @2020. All Rights Reserved. |
StatsToDo: Squential Analaysis Introduction and Explanations
Links : Home Index (Subjects) Contact StatsToDo
|
This page presents a brief assay introducing the programs from StatsToDo that uses sequential analysis.
Sequential analysis is a large and complex subset of statistical procedures that is undergoing developments continuously. It is beyond StatsTodo to provide a comprehensive discussion on the many aspects of this technology. This page will therefore provides only a brief introduction, suffice to help users navigate the programs available in StatsToDo The fixed sample modelStatistics in the late 19th and early 20th century was involved with agriculture and industry, and analysis were usually carried out on batches of data already collected. The early methods were therefore focused around a single examination of the data, probability estimates were based on a single evaluation of the data.A disciplined protocol was therefore developed, where a fixed sample size necessary for making statistical decisions was estimated at the planning stage, and data are not examined until data collection is completed. In fact, when the placebo effect was identified, and that bias from researchers and subjects need to be controlled, it became important that both blinding of all concerned to the treatment and enforced ignorance of the results were observed until data collection is completed. The fixed sample size approach however incurs considerable economic and ethical disadvantages. On many occasions, the effects of treatments are much more obvious than envisaged during planning, and to implement the full sample size incurs unnecessary costs and risks to research subjects. Clinical research also differs from that of agriculture and industry. Instead of processing data as a batch, data is collected in a sequential manner over time as subjects become available, and a research project may extend over a long period. The nature of the data is therefore more suitable for sequential or episodic examination rather than a single analysis at the end of the long period. The development of sequential modelsSequential analysis began as mathematical games and concepts, of analysing how a set of complex probabilities behaves when it is applied repeatedly over time. It remains an esoteric field of mathematics until the Second World War.In the late 1930s and early 1940s there was a massive increase in industrial production of war materials, so there was a need to ensure that products, particularly munitions, were reliable to the users. The testing of these products were not only expensive, but at times destructive (as bullets can only be tested by firing, thus destroying the sample). There was therefore a need to develop a method of minimal testing, yet produce reliable results. Wald, and his group, in the Ministry of Supplies in USA developed the theoretical basis and methodologies of the Squential Probability Ratio Test (SPRT). Instead of defining a sample size, a pair of statistical borders are drawn, one to decide the rejection of the null hypothesis and the other to accept. Data are then obtained sequentially, and plotted against these borders. After each measurement, one of 3 decisions can be made. These are to stop further testing and reject the null hypothesis, to stop further testing and accept the null hypothesis, or to continue testing. The success of this methodology greatly reduced the costs and increase the reliability of supplies, and the method was classified until after the war. In the meantime, another group, under Barnard and Armitage, also developed the concept of sequential analysis. The focus was not only on industrial production, but also testing the efficacy of new products. This resulted in the much quoted book by Armitage on sequential medical trials, focussing on how the methods can be used in drug trials. The focus here is on the Sequential Paired Comparisons, where a paired observation is made, and the difference between the pair tested sequentially against the null hypothesis. Sequential analysis has developed extensively since the mid sixties, and the medical and statistical literature contains many models, some specific to particular research models, and some even developed just to service a particular research project. In the 1990s Whitehead published the theoretical backgrounds and methodologies of unpaired group sequential analysis. This uses the two group controlled trial model, but the statistics was adapted to allow periodic review of the results. StatsToDo presents 5 programs using this approach, comparing two goups using data that are rates of counts, normally distributed means, binomially distributed proportions, ordinal data, and survival rates. The basic model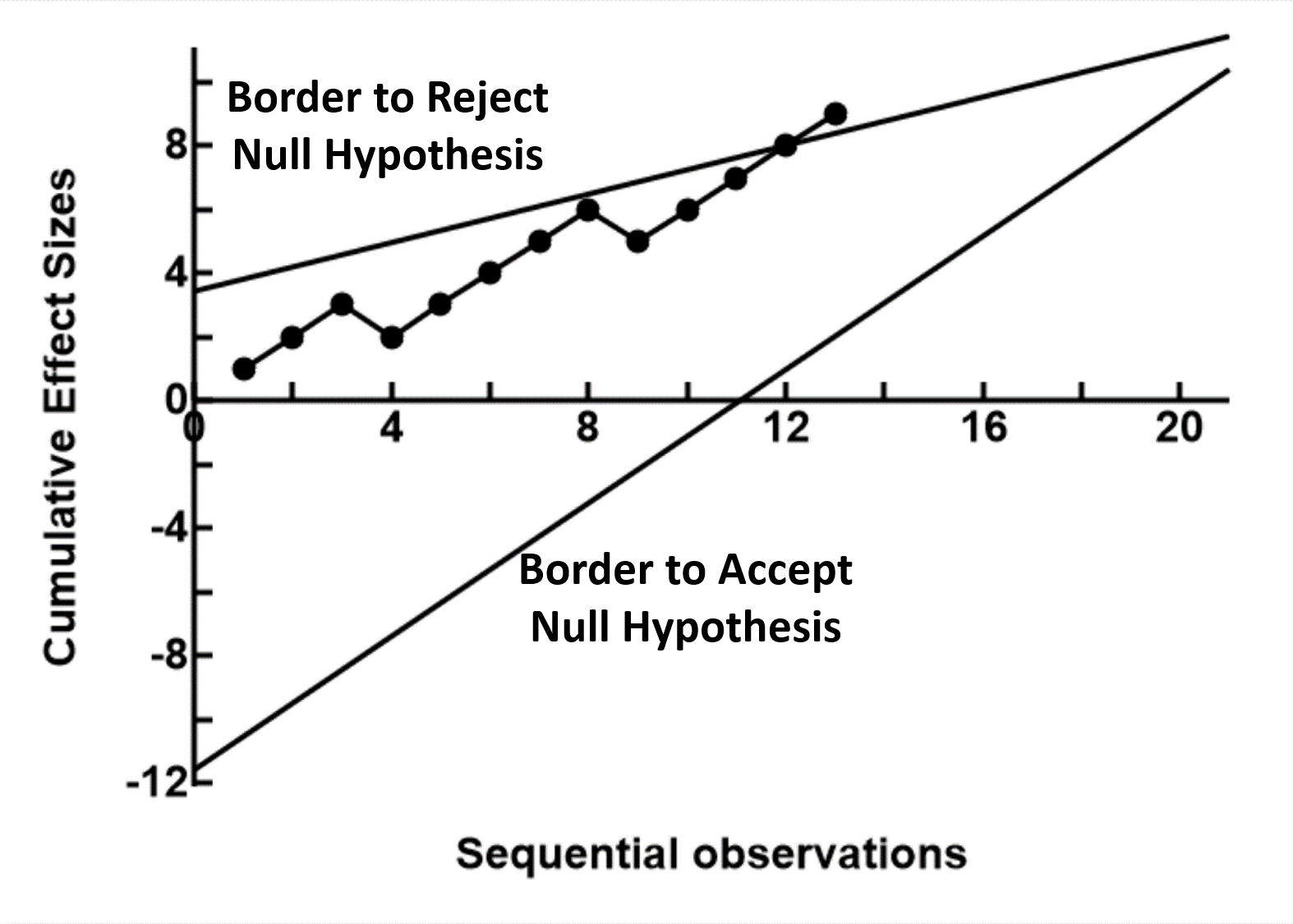 Instead of prescribing a fixed sample size, sequential analysis calculates borders which constrain statistical decisions. Although the shape and size of these borders varies in different models, they conform to a basic pattern as shown to the right
Instead of prescribing a fixed sample size, sequential analysis calculates borders which constrain statistical decisions. Although the shape and size of these borders varies in different models, they conform to a basic pattern as shown to the right
There are usually 2 borders, one to reject the null hypothesis and one to accept the null hypothesis. The relationship between the number of samples taken (the x axis) and some measure of effect size (the y axis) are then plotted on the graph as the information is sampled sequentially. When the plot crosses the rejection border, sampling can stop and a decision to reject the null hypothesis (a difference exists) can be made. If the plot crosses the acceptance border, sampling can stop and a decision to accept the null hypothesis (no significant difference exists) can be made. While the plot remains between the borders, no statistical decision is made other than to continue sampling. In most models, the rejection and acceptance borders converge, or that a third, stopping border is introduced. In these cases the maximum number of samples required is known. In some, particularly the earlier models, the borders are parallel, and in theory sampling can go on forever until one of the borders is crossed. The programs in StatsToDo follows the general trend that a one sided (one tail) statistical test is used, where the hypothesis to be tested is one group has a higher numerical value than the other, and not a difference in either direction. If a two tail test is required, users should use two separate calculations, and half the probability of Type I Error (α) used. Please note : that repeated sequential sampling has a statistical cost, in terms of reduced statistical power. In the planning stage, for the same effect size, the maximum sample size calculated for sequential analysis is larger than that for the fixed sample size model. However, the effect size in the data collected is often much larger or much smaller than that envisaged during planning. When this happens, sequential analysis allows an earlier conclusion to reject or accept the null hypothesis and terminate the study, so the sample size actually used is often smaller than that planned, and smaller than that required in the fixed sample size model. ReferencesBooks with original descriptions used for programs in StatsToDo
|